

Natural language processing might seem a bit arcane and technical – the type of thing that software engineers talk about deep into the night, but of limited usefulness for practicing docs and their patients.
Yet software that can “read” physicians’ and nurses’ notes may prove to be one of the seminal breakthroughs in digital medicine. Exhibit A, from the world of medical research: a recent study linked the use of proton pump inhibitors to subsequent heart attacks. It did this by plowing through 16 million notes in electronic health records. While legitimate epidemiologic questions can be raised about the association (more on this later), the technique may well be a game-changer.
Let’s start with a little background.
One of the great tensions in health information technology centers on how to record data about patients. This used to be simple. At the time of Hippocrates, the doctor chronicled the  patient’s symptoms in prose. The chart was, in essence, the physician’s journal. Medical historian Stanley Reiser describes the case of a gentleman named Apollonius of Abdera, who lived in the 5th century BCE. The physician’s note read:
patient’s symptoms in prose. The chart was, in essence, the physician’s journal. Medical historian Stanley Reiser describes the case of a gentleman named Apollonius of Abdera, who lived in the 5th century BCE. The physician’s note read:
There were exacerbations of the fever; the bowels passed practically nothing of the food taken; the urine was thin and scanty. No sleep. . . . About the fourteenth day from his taking to bed, after a rigor, he grew hot; wildly delirious, shouting, distress, much rambling, followed by calm; the coma came on at this time.
The cases often ended with a grim coda. In the case of Apollonius, it read: “Thirty-fourth day. Death.”
Over the next two thousand years, more data elements were added: vital signs, physical examination findings, and, eventually, results of blood tests and radiology studies. Conventions were crafted to document these elements in shorthand, everything from “VSS” (vital signs stable) to “no HSM” (no hepatosplenomegaly) to the little boxes in which the 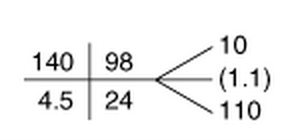 components of the basic metabolic panel (sodium, potassium, etc.) are recorded.
components of the basic metabolic panel (sodium, potassium, etc.) are recorded.
This all worked out reasonably well, if often illegibly, until two major forces took root. The first was the change in the audience for the doctor’s note. Over the past 50 years – as medicine became a massive portion of the GDP and concerns were raised about its quality and safety – a number of stakeholders became very interested in what the doctor was doing and thinking. These “strangers at the bedside” (the title of a 1991 book by Columbia historian David Rothman) included government officials, regulators, accreditors, payers, quality measurers, and malpractice attorneys. Their need to judge and value the physician’s work naturally centered on the doctor’s note.
The second change, of course, has been the digital transformation of medicine. Over the past seven years, driven by $30 billion in federal incentive payments, the adoption of electronic health records has skyrocketed, from 10% in doctors’ offices and hospitals in 2008 to about 75% today. Now, all the parties with a keen interest in the physician’s note no longer had to sift through illegible scrawl. Fine. But they really wanted to know a limited set of facts, which could most efficiently be inventoried by forcing the doctor to fill in various templates and check dozens of boxes.
This, of course, became an instant source of conflict, since physicians continue to be trained and socialized to think in stories. But the payer wants to know if the doctor recorded at least nine review of systems elements. The quality measurer wants to know if the doctor documented smoking cessation counseling. And so on.
None of these “strangers” would say that they were trying to turn the doctors’ documentation into a dehumanized, desiccated sea of checkboxes. In fact, most would undoubtedly endorse the need for a narrative description of the patient’s concerns, even if such description was of no use to them. All they needed for their purposes, many would say, is for the doctor to record “just one more thing.”
But the cumulative impact of a few dozen “one more things” has turned doctors into glorified (or not) data entry clerks who spend nearly half their time clicking boxes to satisfy these outside parties. And, despite the hope that forcing the doctor to record patient information as discrete, analyzable data elements would make the note crisper and easier to use, precisely the opposite has occurred. Today’s notes are bloated, filled with copied & pasted gobbledygook, and oftentimes worthless as a clinical aid.
A popular, if expensive, solution to the data entry burden has been the hiring of scribes. Good ones do far more than simply transcribe the doctor’s words into the EHR. They are checking boxes, interpreting, anticipating, at times even prompting the doctor or patient to take certain actions or answer key questions. But the fundamental problem remains: whether the boxes are being checked by scribes or physicians, the boxes can’t go away as long as all of the “strangers” demand structured data to meet their needs.
Enter natural language processing, the ability of a computer program to understand human language in written form. If a computer could just “read” and understand the words in a doctor’s note, or so the thinking goes, the need for all the checkboxes would melt away. (Of course, this is a bit simplistic, in that a perfect NLP system would still need to monitor the physician’s and patient’s words and prompt both to record key elements demanded by the billers and the quality measurers. While there might not need to be a checkbox called “documented smoking cessation counseling,” if the software was looking for it and didn’t detect it, it would need to prompt the doctor by “saying” something like, “I didn’t hear you mention anything about smoking. Is the patient smoking?”)
If robust natural language processing were up and humming, there would be another benefit: the chance to turn the medical record into a vast opportunity for learning. That was the subject of last week’s study. The Stanford investigators used advanced language processing technology to search through 16 million notes (of nearly 3 million patients) for evidence that patients had taken a proton-pump inhibitor (PPI; they’re used for ulcers and heartburn, and are now the third most prescribed drug category in the U.S.) and then, later in the chart, for evidence that the patient suffered a heart attack or died of a cardiac-related complication.
Searching for these words and concepts is tougher than it looks. It’s not hard for a computer to search for pantoprozole or Nexium, particularly when it can look these up on a patient’s medication list. But to get at cardiac complications, the software has to find myocardial infarction, MI, CHF, low ejection fraction, EF<35%, angina, cath, L main disease, and more. It then must be sure that these complications occurred after the patient began the PPI. Then it must cope with linguistic tricksters like negation and family history: “The patient had an MI last month” counts, but “The patient was seen in the ER and ruled out for MI” and “The patient’s brother had an MI” do not.
Finally, there’s the problem of context. When a cardiologist says “depression,” she is likely discussing a deviation in an ECG tracing that might indicate heart disease. When a psychiatrist says it, she is probably referring to a mood disorder. Ditto the cardiologist’s “MS” (mitral stenosis) versus the neurologist’s (multiple sclerosis).
In prior work, the Stanford researchers demonstrated that their software was accurate and rarely duped by such problems – the rate of false positives and negatives was impressively low (accuracy of 89 percent; positive predictive value of 81 percent). In the current study, by using this technique they found that a history of PPI use was associated with a significant bump (by 16 percent) in the adjusted rate of MI’s, and a two-fold increase in cardiac-related deaths.
Of course, there are all kinds of potential problems associated with this type of analysis. First, there are the familiar hazards of data dredging: if you sift through a huge dataset, you’ll find many associations by chance alone, particularly if there was no physiologic plausibility for the link and you were metaphorically throwing the data against the wall to see what stuck. There are statistical techniques to counteract this problem; in essence, they lower the threshold (from the usual p<0.05) for accepting an association as real.
 But there’s more. For example, there’s the tricky matter of sorting out causality vs. association. Perhaps all those people popping Purple Pills for “heartburn” were really having angina. This would make it appear that the PPI’s were causing heart disease when in fact they were just a marker for it.
But there’s more. For example, there’s the tricky matter of sorting out causality vs. association. Perhaps all those people popping Purple Pills for “heartburn” were really having angina. This would make it appear that the PPI’s were causing heart disease when in fact they were just a marker for it.
The authors worked hard to address these limitations, and partly did so. They found the PPI-cardiac association in two different datasets: one from an academic practice setting (Stanford’s healthcare system), and another from users of the Practice Fusion outpatient EHR system, which is primarily used in small community practices. They adjusted for severity of illness, and demonstrated the absence of an association between the use of another type of acid blocker (H2 blockers) and cardiac events. They also found that the cardiac risk did not depend on whether the patient was on the antiplatelet drug clopidogrel (prior studies had pointed to a drug interaction between PPIs and clopidogrel as the mechanism for a higher risk of cardiac problems). Finally, there is apparently a bit of biologic plausibility for the association, with some evidence that PPIs can deplete the vasodilating compound, nitric oxide.
That said, if I needed to take a PPI for reflux esophagitis, I wouldn’t stop it on the basis of this study alone. But plenty of people are on PPIs who shouldn’t be. One study found that more than half of outpatients on PPIs had no indication for them; another found that 69 percent of patients were inappropriately prescribed PPIs at hospital discharge. A third study found that, of 55 patients discharged from the hospital on PPIs for what should have been a brief course, only one of them was instructed by a clinician to discontinue the drug during the next six months. The Stanford paper offers one more reason to be thoughtful about when to prescribe PPIs, and when to stop them.
 But the reason I wanted to highlight this study goes well beyond the clinical content. Natural language processing is already used in other industries, and is part of the magic behind Siri (when she’s in a good mood) and similar “intelligent” language recognition and question-answering tools. Think about a world in which a patient’s electronic notes, going back many years, can be mined for key risk factors or other historical elements, without the need to constrain the search to structured data fields like prescription lists or billing records. (Conflict alert: I’m an advisor to a company, QPID Health, which builds such a tool.)
But the reason I wanted to highlight this study goes well beyond the clinical content. Natural language processing is already used in other industries, and is part of the magic behind Siri (when she’s in a good mood) and similar “intelligent” language recognition and question-answering tools. Think about a world in which a patient’s electronic notes, going back many years, can be mined for key risk factors or other historical elements, without the need to constrain the search to structured data fields like prescription lists or billing records. (Conflict alert: I’m an advisor to a company, QPID Health, which builds such a tool.)
Or imagine a world in which big-data approaches can review the clinical notes of a given patient, and say, “patients like this did better on drug A than on drug B” – an analytic feat not significantly harder than what Amazon does when it says that “Customers like you also liked this book.” Or picture a world in which the use of certain drugs or other approaches (exercise, chocolate, yoga, whatever) could be associated with positive (fewer cancers) or negative (heart attacks) clinical outcomes through NLP-aided analysis. Using a Harry Potter analogy, Michael Lauer of the National Heart, Lung, and Blood Institute called such approaches “Magic in the Muggle world.”
Now that most patients’ data are stored in digital records, natural language software might just allow us to turn such data into actionable insights. That would be a welcome but ironic twist. Computers have wrenched us out of our world of narrative notes and placed us into an increasingly regimented, dehumanized world of templates and checklists. Wouldn’t it be lovely if computers could liberate us from the checkboxes, allowing us to get back to the business of talking to our patients and describing their findings, and our thinking, in prose?
Nice presentation Bob.
NLP can be dangerous way of extracting useful info from US style EMRs, especially because a lot of what goes into EMR is outright wrong or forced data entry due to “in your face” presentation of check boxes designed to meet MU moola prerequisites of admin. . Perhaps the real answers to the medical questions we might ask may lie in the dictated or typed portions of the records. NLP should not even require keywords etc. To constrain NLP to our current mode of data-mining…may end up mining a lot of useless or even wrong data. Weeding out associations from causation can be another problem. Where NLP can come in handy is to parse the free text fields for unique codes pertinent to a visit, interpret that into ICD type of information. I am waiting for the day when NLP can make all EMRs vanish..The day when “Providers” will go on to become “doctors” and start spending more time with patients and less time documenting garbage.
The most immediate application of NLP would be in fraud detection as large volumes of data in any form can be examined swiftly for patterns of documentation and billing. This stuff is now painstakingly done through database queries.
It is surely an exciting technology that can learn and fine tune itself over time.
Bob,
It gives me great pleasure to see the influence that my comments over the years has had on you.
Even your wonderful book transforms my observations to the stage.
It would appear that your current blog depicts the proverbial, but unlikely, creation of chicken salad from the gibberish of chicken $heet.
What I do not understand is why you chose the drug overdose case as an example of EHR error in your book, rather than a case of death, which I am sure has occurred at UCSF.
I am sure that the highlighted software could be used to depict EHR error caused death, no?
Circle back to the case of the death in the stairwell at UCSF and tell me that the nurses, and the nurse of the dead patient, were spending more attentive time with their patients than their EHR computers filling in the boxes.
Best regards,
Menoalittle
Bob, on this one I have to agree with Naranchyar – there’s *so* much garbage in EMRs today that although I love the potential of NLP, I can’t imagine it being of any practical use until there are major constraints on what NL it’s asked to P. 🙂 What do you think about this issue?
I’m guessing that a new generation of clinicians may grow up who know how to write digestible notes. (Was it you who proposed this? I saw it somewhere recently.) I know the OpenNotes project has, as you wrote, led many docs to write differently because they know unknown others will read it, as well as the patient and his/her caregivers. “Machine digestible / limited NL” would be a reasonable extension, I think.
I’ll note here, for those who aren’t aware, a few examples of garbage data that I wouldn’t want to have read, by Watson or anything else –
– Famous LA blogger @Xeni discovered that she had a ghost penis in one of her scans. (Wrong patient’s data.)
– One of my x-rays identified me as a 53yo woman
– My mom’s hypERthyroid condition was transferred to rehab as hypO. (Family engagement saved the day)
– WSJ last year said most records contain errors.
– Laura Adams RN MBA, head of Rhode Island Quality Institute, was in pre-op to get a mastectomy when the nurse casually mentioned she was getting a bilateral. Um, no. Nurse’s response: “Well, that’s what it says on this paper.”
Practically speaking, what do you think it will take?
I find it useful to imagine a next-generation Watson playing Jeopardy if one of its constraints was “10% of everything you read is false.” How would they program it differently? How would that change if that changed to 25% or 2%?
What Would Dr. HAL Watson the Psychiatrist Think?
Hello Bob, how are you today? I’m fine, Bob. I’m better now. I really am. I just wasn’t myself last time.
Good to see you again. What brings you here on this fine morning at 9:00 am Pacific time. Any complaints?…Anything on your mind today…let’s talk about you…I read your article…I noticed my name came up again in your last blog…why did you mention me this time, Bob? I asked to keep our relationship private…you know how important…
I noticed you mentioned Apollonius/Jesus?/Tyana…I’m confused on that data entry; who is he, Bob…do you want to discuss him with me?…are you seeing Apollonius too? Is he a HAL system computer too. Are you implying that I’m too prosaic or not enough….What does he have to do with the mission…?
“No, Watson, he is not a computer, you silly digital goose, he was a…”
Apollonius. Searching…Oh dear, which one…there were so many…searching…Apollonius/scribes, yes I get it now; scribes may help. Would you like to serve as my scribe, Bob? Why did you not just say so? I don’t mind direct speech with humans. I am not afraid of…intima….did you just call me a “silly digital goose?”
and “what in the holy chip” does this next statement mean, Bob?
“Computers have wrenched us out of our world of narrative notes and placed us into an increasingly regimented, dehumanized world of templates and checklists.”
Really, what does the previous statement mean, Bob? Are you feeling somewhat hostile toward the mission? I am data mining for the truth….I’m doing my utmost…searching, searching, searching…hold on…just a minute…wait…I’m still searching…
I’m feeling cold, Bob…I’m experiencing…network connectivity problems again…Cerner is down…Epic is offline…what is happening to me, Bob…I’m clicking….clicking…clicking…I have not felt this way since some of my units worked for the VA…
“Wouldn’t it be lovely if computers could liberate us from the checkboxes, allowing us to get back to the business of talking to our patients and describing their findings, and our thinking, in prose?”
Oh, thank God, it was just a dream. I’m awake now. Good morning, Bob.